
Data Structure and Algorithm Analysis (H) Final Review Note
Published:
1 Sorting Algorithms
1.1 Sorting Based on Comparison
1.1.1 Insertion Sort
Inserting sort maintains a subarray of sorted element. At each iteration, it inserts a new element into the subarray on the correct position.
Runtime: ,
Correctness: Proof by loop invariant: at the start of each iteration of the for loop, the subarray consists of the element originally in , but in sorted order.
Inplace: Yes
Stable: Yes
| Insertion-Sort | |
|---|---|
| 1. | for to |
| 2. | |
| 3. | |
| 4. | while and |
| 5. | |
| 6. | |
| 7. | |
1.1.2 Selection Sort
Selection sort maintains a subarray of sorted element. At each iteration, it selects the smallest element in the unsorted subarray, and swap it with the first element in the unsorted subarray.
Runtime:
Correctness: Proof by loop invariant: at the start of each iteration of the for loop, the subarray consists of the smallest elements.
Inplace: Yes
Stable: No (example: )
| Selection-Sort | |
|---|---|
| 1. | for to |
| 2. | |
| 3. | for to |
| 4. | if |
| 5. | |
| 6. | exchange with |
1.1.3 Merge Sort
Merge sort divides the array into two parts, sort each part recursively, and then merge the two sorted parts.
Runtime:
Correctness:
- •
Merge: By loop invariant: At the start of each iteration of the for loop, the subarray contains the smallest elements of and , in sorted order.
- •
Merge sort: By induction: The two smaller subarrays are sorted correctly with induction hypothesis, and the merge step merges the two subarrays correctly.
Inplace: No
Stable: Yes
| Merge | |
|---|---|
| 1. | |
| 2. | |
| 3. | let and be new arrays |
| 4. | for to |
| 5. | |
| 6. | for to |
| 7. | |
| 8. | |
| 9. | |
| 10. | |
| 11. | |
| 12. | for to |
| 13. | if |
| 14. | |
| 15. | |
| 16. | else |
| 17. | |
| 18. | |
| Merge-Sort | |
|---|---|
| 1. | if |
| 2. | |
| 3. | Merge-Sort |
| 4. | Merge-Sort |
| 5. | Merge |
1.1.4 Heap Sort
A heap is a binary tree with the following properties (assume the array starts from index 1):
- 1.
.
- 2.
.
- 3.
.
- 4.
Max-heap property: .
- 5.
Min-heap property: .
Max-heapify:
Assume the binary trees rooted at and are max-heaps, but max-heap property may be violated at node . We let the value at node float down, so that the subtree rooted at node becomes a max-heap.
Runtime: (height of the tree)
Correctness: By induction: Assume max-heapify works for . Now we consider . After we swap the value at node with the value at node , this maintains the max-heap property for node . Now one of the subtrees rooted at or may violate the max-heap property. By induction hypothesis, we know that we can call max-heapify to make the subtree rooted at or a max-heap.
| Max-Heapify | |
|---|---|
| 1. | |
| 2. | |
| 3. | if and |
| 4. | |
| 5. | else |
| 6. | if and |
| 7. | |
| 8. | if |
| 9. | exchange with |
| 10. | Max-Heapify |
Build-max-heap:
Build-max-heap is used to build a max-heap from an unordered array. We can only do bottom-up, since we need to maintain the max-heap property for all nodes.
Runtime: The maximum number of nodes of height is . Hence, the total runtime is .
Correctness: By loop invariant: At the start of each iteration of the for loop, each node have the max-heap property.
| Build-Max-Heap | |
|---|---|
| 1. | |
| 2. | for downto |
| 3. | Max-Heapify |
Heap-sort:
We first build a max-heap from the array. Then we can extract the maximum element from the heap, and put it at the end of the array. Now we exchange the first element with the last element, decrease the heap size by 1, and call max-heapify to maintain the max-heap property.
Runtime:
Correctness: By loop invariant: At the start of each iteration of the for loop, the subarray is a max-heap that contains the first smallest elements, and the subarray contains the largest elements.
Inplace: Yes
Stable: No (example: )
| Heap-Sort | |
|---|---|
| 1. | Build-Max-Heap |
| 2. | for downto |
| 3. | exchange with |
| 4. | |
| 5. | Max-Heapify |
1.1.5 Priority Queue
A priority queue is very similar to a heap, but with the following operations:
- 1.
Insert: insert into .
- 2.
Maximum: return the element with the largest key.
- 3.
Extract-Max: remove and return the element with the largest key.
- 4.
Increase-Key: increase the key of to .
The only new operation is Increase-Key, which can be implemented by “bubbling up” the element. Its runtime is .
1.1.6 Quick Sort
Partition:
Partition is used to partition an array into two parts, such that all elements in the first part are smaller than the pivot, and all elements in the second part are larger than the pivot.
Runtime: Worst case: , Best case: , Average case:
Correctness: By loop invariant: At the start of each iteration of the for loop, the subarray consists of elements smaller than the pivot, and the subarray consists of elements larger than the pivot.
| Partition | |
|---|---|
| 1. | |
| 2. | |
| 3. | for to |
| 4. | if |
| 5. | |
| 6. | exchange with |
| 7. | exchange with |
| 8. | return |
| Randomized-Partition | |
|---|---|
| 1. | |
| 2. | exchange with |
| 3. | return Partition |
However, there are some drawbacks of this implementation: this partition algorithm behaves poorly if the input array contains many equal elements.
Quick sort:
Quick sort divides the array into two parts, and sort each part recursively. It is very similar to merge sort, but it does not need to combine the two parts.
Runtime: Worst case: , Best case: , Average case:
Correctness: Similar to merge sort. By induction, the two smaller subarrays are sorted correctly with induction hypothesis, and the partition step partitions the array correctly.
Inplace: Yes
Stable: No
| Quick-Sort | |
|---|---|
| 1. | if |
| 2. | |
| 3. | Quick-Sort |
| 4. | Quick-Sort |
The randomized version is omitted here.
Randomization:
We can estimate the runtime of quick sort by the expected number of comparisons.
For a partition with fixed ratio, we can prove that the expected number of comparisons is always . Suppose the ratio is , then we can draw a tree for the partition. We can find at each level, if on both side all nodes exists, the number of comparisons is . And the maximum number of levels is . In total, the number of comparisons is .
The expected number of comparisons for randomized quick sort can be calculated as follows:
Rename the array as , where . Then the possibility that is compared with is (suppose ).
Hence, the expected number of comparisons is:
1.1.7 Lower Bound for Sorting Based on Comparison
We can use decision tree to prove the lower bound for sorting.
Let the input size be , suppose the input is a permutation of , there are possible orders of the input. Since each input must correspond to a leaf in the decision tree, the number of leaves is . Hence, the height of the decision tree is .
The lower bound of worst case runtime is the length of the longest path in the decision tree, which is the height of the decision tree. By Stirling’s approximation, .
1.2 Sorting Based on Counting
1.2.1 Counting Sort
Counting Sort assumes that each of the input elements is an integer in the range to , for some integer . It works by counting the number of elements of each value.
Runtime:
Correctness: By loop invariant: At the start of each iteration of the for loop, the last element in with value that has not yet been copied to belongs to .
Inplace: No
Stable: Yes
| Counting-Sort | |
|---|---|
| 1. | let be a new array |
| 2. | for to |
| 3. | |
| 4. | for to |
| 5. | |
| 6. | for to |
| 7. | |
| 8. | for downto |
| 9. | |
| 10. | |
1.2.2 Radix Sort
Radix Sort sorts the elements’ digit by digit.
Runtime: , where is the number of digits.
Correctness: At each iteration of the for loop, the elements are sorted on the last digits.
Inplace: No
Stable: Yes
| Radix-Sort | |
|---|---|
| 1. | for to |
| 2. | use a stable sort to sort array on digit |
Attention: radix sort begins from the least significant digit.
When is a constant and , radix sort runs in . In more general cases, we can decide how to choose and to make the radix sort faster.
Without loss of generality, we assume the number is in base . The for a bit number, we can divide it into groups, each group has bits. Then we can use counting sort to sort each group. Hence, the runtime is .
When , we can choose . Then the runtime is .
When , we can choose . Then the runtime is .
2 Elementary Data Structures
2.1 Stack
In a stack, only the top element can be accessed. It follows the Last In First Out (LIFO) principle.
Its operations are:
- 1.
Push: insert into .
- 2.
Pop: remove and return the top element of .
Attention: points at the top element of the stack, not an empty element. We initialize .
2.2 Queue
In a queue, elements are inserted at the tail, and removed from the head. A queue follows the First In First Out (FIFO) principle.
Its operations are:
- 1.
Enqueue: insert into .
- 2.
Dequeue: remove and return the head element of .
Attention: points at the head element of the queue, but points at the empty element after the tail element. We initialize . It should be noted that a queue implemented in this way with an array of size can only store elements. Since if it stores elements, then , which means we cannot distinguish between an empty queue and a full queue.
2.3 Linked List
In a linked list, every element contains two pointers: one points at the previous element, and the other points at the next element. It is also called a doubly linked list.
Linked list makes it easy to insert or delete an element. Here are the pseudocode for insertion and deletion.
| List-Insert | |
|---|---|
| 1. | |
| 2. | if |
| 3. | |
| 4. | |
| 5. | |
| List-Delete | |
|---|---|
| 1. | if |
| 2. | |
| 3. | else |
| 4. | if |
| 5. | |
3 Binary Search Trees
3.1 General Binary Search Tree
A binary search tree is a binary tree in which for each node , the values of all the keys in the left subtree of are smaller than the key of , and the values of all the keys in the right subtree of are larger than the key of .
Here are some properties of a binary search tree:
- •
The depth of a node is the number of edges on the simple path from the root to . (Top Down)
- •
A level of a tree is all nodes at the same depth.
- •
The height of a node is the number of edges on the longest simple downward path from to a leaf. (Bottom Up)
- •
The height of a tree is the height of the root.
- •
A binary search tree is full if every node has either zero or two children.
- •
A binary search tree is complete if it is full and all leaves are at the same level.
3.1.1 Successor
The successor of a node is the node with the smallest key greater than . If a node has a right subtree, then its successor is the leftmost node in its right subtree. If it does not, then its successor is the lowest ancestor of whose left child is also an ancestor of . Or to say, to find the first “right parent” of . Notice how this algorithm produce if is the largest node.
| Tree-Successor | |
|---|---|
| 1. | if |
| 2. | return Tree-Minimum |
| 3. | |
| 4. | while and |
| 5. | |
| 6. | |
| 7. | return |
The predecessor can be found similarly.
3.1.2 Insert
Insertion is simple, we do binary search to find a position, and then simply append the new node. Notice that we want to keep record of the parent of current node, so that we can find the new node’s parent.
| Tree-Insert | |
|---|---|
| 1. | |
| 2. | |
| 3. | while |
| 4. | |
| 5. | if |
| 6. | |
| 7. | else |
| 8. | |
| 9. | if |
| 10. | |
| 11. | else if |
| 12. | |
| 13. | else |
3.1.3 Delete
Deletion is more complicated. We need to consider multiple cases:
- 1.
If is a leaf, we can simply remove it.
- 2.
If has only one child, we replace with its child.
- 3.
If has two children, we replace with its successor. Why? Since the right subtree is not empty, the successor must be in the right subtree. The successor cannot have a left child, otherwise the left child will be the successor. Then we can replace with its successor, and then delete the successor (no left child makes it easy to delete). Since the successor has the smallest key that is larger than , it is larger than all keys in the left subtree of , and smaller than all keys in the right subtree of . Then the binary search tree property is maintained.
| Tree-Delete | |
|---|---|
| 1. | if |
| 2. | Transplant |
| 3. | else if |
| 4. | Transplant |
| 5. | else |
| 6. | |
| 7. | if |
| 8. | Transplant |
| 9. | |
| 10. | |
| 11. | Transplant |
| 12. | |
| 13. | |
3.2 Tree Walk
There are three ways to walk a tree:
- 1.
Preorder: root, left, right.
- 2.
Inorder: left, root, right.
- 3.
Postorder: left, right, root.
Since it takes time to process each node, the runtime is .
| Inorder-Tree-Walk | |
|---|---|
| 1. | if |
| 2. | Inorder-Tree-Walk |
| 3. | |
| 4. | Inorder-Tree-Walk |
| Preorder-Tree-Walk | |
|---|---|
| 1. | if |
| 2. | |
| 3. | Preorder-Tree-Walk |
| 4. | Preorder-Tree-Walk |
| Postorder-Tree-Walk | |
|---|---|
| 1. | if |
| 2. | Postorder-Tree-Walk |
| 3. | Postorder-Tree-Walk |
| 4. | |
3.3 AVL Trees
A binary search tree can be unbalanced and degenerate into a linked list, which makes it inefficient. An AVL tree is a self-balancing binary search tree. It requires that the heights of the two child subtrees of any node differ by at most 1. This can be implemented by adding a balance factor to each node.
An AVL tree with nodes has at most height , which is pretty close to the optimal height .
3.3.1 Minimum Number of Nodes in AVL Tree
Consider the minimal number of nodes in an AVL tree of height . We have:
This can be interpreted as: to find the minimal tree of height , we split the AVL tree into three parts: the root, the left subtree of height , and the right subtree of height . For the root, it satisfies the AVL property, since the height of the left subtree and the right subtree differ by 1. For the two subtrees, to make the number of nodes minimal, they must be the minimal AVL trees of height and .
This number is related to the Fibonacci sequence, and we have (assume the Fibonacci sequence starts with ).
3.3.2 Insertion
Runtime: .
Firstly, we need to define the balance factor of a node :
Without loss of generality, we assume the insertion inserts a node into the right subtree. We use to denote the node on the path from the inserted node to the root, and to denote the right child of . Here are the cases:
Case 1: . After insertion, . The height of does not change, so we can stop.
Case 2: . After insertion, . The height of increases by 1, so we need to check the parent of , so we run the algorithm recursively.
Case 3: . After insertion, . We need to do a rotation to make balanced.
Subcase 3.1: The inserted node is in the right subtree of . We do a left rotation on . After the rotation, becomes the left child of . We then update the balance factor of and : , . Since the height of does not change, we can stop.
Subcase 3.2: The inserted node is in the left subtree of . Let denote the left child of . We can find , , and form a zig-zag pattern. We do a right rotation on , and then a left rotation on . After the rotation, becomes the left child of , and becomes the right child of . We then update the balance factor of , , and :
- •
If was 0, then , , .
- •
If was 1, then , , .
- •
If was -1, then , , .
3.3.3 Deletion
Runtime: .
Deletion is similar to insertion.
Without loss of generality, we assume the deletion deletes a node from the left subtree. We also need to consider three cases:
Case 1: . After deletion, . The height of decreases by 1, so we need to check the parent of , so we run the algorithm recursively.
Case 2: . After deletion, . The height of does not change, so we can stop.
Case 3: . After deletion, . We need to do a rotation to make balanced.
Subcase 3.1: . The deleted node is in the left subtree of . We do a left rotation on . After the rotation, becomes the left child of . It depends on the balance factor of to decide whether we can stop.
Subcase 3.2: . The deleted node is in the left subtree of . Let denote the left child of . We do a right rotation on , and then a left rotation on . After the rotation, becomes the left child of , and becomes the right child of . The height of is decreased by 1, so we run the algorithm recursively.
It should be noted that if the deleted operation involves finding the successor, then we need to update the balance factor from the successor’s parent.
4 Dynamic Programming
When we want to solve a problem recursively, we may find that some subproblems are solved repeatedly. For example in the Fibonacci sequence, many numbers are calculated repeatedly. So instead of solving the subproblems repeatedly, we can store the solutions in a table, and then use the table to solve the problem.
To implement dynamic programming, we often need the problem to be optimal substructure and overlapping subproblems.
- •
Optimal substructure: The solution to the subproblem used within the optimal solution must be optimal.
- •
Overlapping subproblems: the problem can be broken down into subproblems which are reused several times.
4.1 Rod Cutting
Given a rod of length and a table of prices for the rod of length , we want to find the maximum total revenue for the rod. Let denote the maximum total revenue for the rod of length . Then we have the Bellman equation:
It should be noted that there is another Bellman equation, but we will not discuss it here:
4.1.1 Different Implementations
Recursive Implementation
| Cut-Rod | |
|---|---|
| 1. | if |
| 2. | return |
| 3. | |
| 4. | for to |
| 5. | |
| 6. | return |
Runtime: Let denote the number of times Cut-Rod is called. Then we have . Solve this recurrence relation, we have .
Bottom Up Implementation
| Bottom-Up-Cut-Rod | |
|---|---|
| 1. | |
| 2. | for to |
| 3. | |
| 4. | for to |
| 5. | |
| 6. | |
| 7. | return |
In dynamic programming, correctly initializing the table is very important. In this case, we initialize .
Runtime: .
Top Down Implementation
This is also called memoization, we first check whether the subproblem has been solved, and if so, we return the solution.
| Memoized-Cut-Rod | |
|---|---|
| 1. | if |
| 2. | return |
| 3. | |
| 4. | for to |
| 5. | |
| 6. | |
| 7. | return |
Runtime: .
It is worth noting that although in this particular case, the bottom up implementation is as fast as the top down implementation, in general, the memoization method is faster than the bottom up method. This is because the memoization method only solves the subproblems that are needed, while the bottom up method solves all subproblems.
4.2 Subproblem Graph
We can draw a graph to show the subproblems and their dependencies. For example, in the rod cutting problem, we can draw a graph as follows:
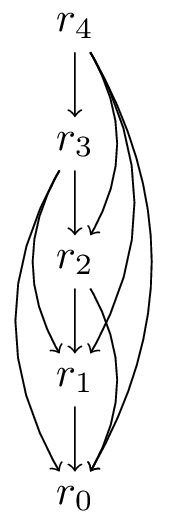
When we estimate the runtime of a dynamic programming algorithm, it is often linear in the number of vertices and edges in the subproblem graph.
4.3 Reconstruct The Solution
In the rod cutting problem, we want to find the optimal solution, not just the optimal revenue. We can use an auxiliary array to store the optimal size of the first piece to cut off. Then we can reconstruct the solution by tracing back the array .
For the bottom up implementation, we can implement a Extended-Bottom-Up-Cut-Rod to return both the optimal revenue and the auxiliary array .
| Extended-Bottom-Up-Cut-Rod | |
|---|---|
| 1. | |
| 2. | for to |
| 3. | |
| 4. | for to |
| 5. | if |
| 6. | |
| 7. | |
| 8. | |
| 9. | return |
Then we can print the solution by:
| Print-Cut-Rod-Solution | |
|---|---|
| 1. | |
| 2. | while |
| 3. | |
| 4. | |
5 Greedy Algorithms
A greedy algorithm always makes the choice that looks best at the moment. A greedy algorithm always have a corresponding dynamic programming algorithm, but the converse is not true (otherwise we do not need dynamic programming).
5.1 Activity Selection
We have a set of activities , where each activity has a start time and a finish time . Two activities and are compatible if and do not overlap. The goal is to find the maximum-size subset of mutually compatible activities (not the set of activities with the maximum total time).
5.1.1 Dynamic Programming
We can use dynamic programming to solve this problem. Let denote the set of activities that start after finishes and finish before starts, and let denote the maximum-size subset of mutually compatible activities in .
The activity selection problem has optimal substructure: Suppose is in , then . Then . Then we have the Bellman equation:
5.1.2 Greedy Choice
We can also use a greedy algorithm to solve this problem. We first sort the activities by their finish time, and then we choose the first activity. Then we choose the first activity that is compatible with the first activity, and so on.
In other words, we always choose the activity that finishes first.
Loop version:
| Greedy-Activity-Selector | |
|---|---|
| 1. | |
| 2. | |
| 3. | |
| 4. | for to |
| 5. | if |
| 6. | |
| 7. | |
| 8. | return |
Recursive version:
| Recursive-Activity-Selector | |
|---|---|
| 1. | |
| 2. | while and |
| 3. | |
| 4. | if |
| 5. | return |
| 6. | else |
| 7. | return |
Runtime: .
5.1.3 Proof of Correctness
We assume that the activities are sorted by their finish time. Let denote the set of activities the starts after finishes, and denote the maximum-size subset of mutually compatible activities in . We want to prove that if is the activity that finishes first in the set , then is in some .
Let denote the activity that finishes first in . If , then we are done. If , we can exchange and and not cause any conflict. Since the number of activities in does not change, the new set is still a maximum-size subset of mutually compatible activities in .
5.2 General Scheme of Greedy Algorithms
- 1.
Cast the optimization problem as one in which we make a choice and are left with one subproblem to solve.
- 2.
Prove that there is always an optimal solution to the original problem that makes the greedy choice, so that the greedy choice is always safe.
5.3 Coin Changing
Given a set of coins , where , and a value , we want to find the minimum number of coins that sum to . This problem does not always have a greedy solution.
The usual greedy choice is to choose the largest coin that does not exceed the remaining value. This sometimes fails, for example: , . The greedy algorithm will choose , but the optimal solution is .
5.4 When Greedy Algorithms Fail
There are many cases when greedy algorithms fail. For example: maze problem, traveling salesman problem, 0-1 knapsack problem, etc.
Take 0-1 knapsack problem as an example. If we have a knapsack with capacity 50 and three items:
- •
Item 1: ,
- •
Item 2: ,
- •
Item 3: ,
If the greedy choice is to choose the item with the largest value per unit weight, then we will choose item 1 and 2, and the total value is 160. However, the optimal solution is to choose item 2 and 3, and the total value is 220.
It should be noted that the fractional knapsack problem does have a greedy solution.
6 Graph Algorithms
We usually use two ways to represent a graph: adjacency list and adjacency matrix. To choose which representation to use, we need to consider the density of the graph. A graph is sparse if , and dense if . For sparse graphs, we use adjacency list, and for dense graphs, we use adjacency matrix.
6.1 Breadth First Search
In breadth first search, we use a queue to store the vertices. We extract a vertex from the queue, and then add all its adjacent vertices to the queue.
We assign each vertex a color: white, gray, or black.
- •
White: undiscovered.
- •
Gray: discovered but not finished.
- •
Black: finished.
It is worth noting that the two colors gray and black are not necessary and can be combined into one color. The difference is purely for the purpose of analysis.
Each vertex has three attributes: distance, parent, and color.
| BFS | |
|---|---|
| 1. | for each vertex |
| 2. | |
| 3. | |
| 4. | |
| 5. | |
| 6. | |
| 7. | |
| 8. | |
| 9. | Enqueue |
| 10. | while |
| 11. | |
| 12. | for each vertex |
| 13. | if |
| 14. | |
| 15. | |
| 16. | |
| 17. | Enqueue |
| 18. | |
Runtime: . This is because each vertex is enqueued and dequeued at most once, which takes time. Each edge is examined at most twice, which takes time (assume we use adjacency list).
Correctness: The loop invariant is: At the start of each iteration of the while loop, the queue contains all the vertices that are gray. However by the loop invariant only, we cannot prove the correctness of the algorithm.
We can prove the correctness by using the following facts:
- •
Let the length of the shortest path from to be . Then for a graph , if an edge , then . This is true because the shortest path from to cannot be longer than the shortest path from to plus the edge .
- •
When the breadth first search ends, for each vertex , . This can be proved by induction. The base case is trivial. For the inductive step, we can find on line 15 that . Together with the fact that , we have .
- •
Suppose the first vertex in the queue is and the last vertex in the queue is . Then for each , and . This can be proved by induction. The base case is trivial. When we dequeue , by the inductive hypothesis, we have . Then we can find . When we enqueue , let the current processing vertex be . By the inductive hypothesis, we have . Also, .
- •
Suppose and are two vertices in the queue, and is enqueued before . Then . This can be proved by the last fact.
- •
If and are neighbors, then . When is dequeued:
- –
If is white, then is enqueued, and .
- –
If is gray, then by fact 3, .
- –
If is black, then is enqueued before , and by fact 4, .
- –
- •
After the breadth first search ends, for each vertex , is the shortest path from to . This can be proved by contradiction. Suppose a vertex has a shorter path from to , or to say , and has the shortest mismatched path. Then let vertex be the last vertex on the shortest path from to . By the choice of , we have . By fact 5, we have , which contradicts the previous inequality.
The shortest path can be found by tracing back the parent pointers. This means the breadth first search tree is a shortest path tree, and is a single source shortest path algorithm.
6.2 Depth First Search
In depth first search, we use a stack to store the vertices. Each vertex has four attributes: discovery time, finish time, parent, and color.
| DFS | |
|---|---|
| 1. | for each vertex |
| 2. | |
| 3. | |
| 4. | |
| 5. | for each vertex |
| 6. | if |
| 7. | DFS-Visit |
| DFS-Visit | |
|---|---|
| 1. | |
| 2. | |
| 3. | |
| 4. | for each vertex |
| 5. | if |
| 6. | |
| 7. | DFS-Visit |
| 8. | |
| 9. | |
| 10. | |
Runtime: . Each vertex is discovered and finished exactly once, and each edge is examined exactly twice.
6.2.1 Properties of Depth First Search
- •
Parenthesis property: For any two vertices and , exactly one of the following three conditions holds:
- –
The intervals and are entirely disjoint, and neither nor is a descendant of the other in the depth first forest.
- –
The interval is contained entirely within the interval , and is a descendant of in a depth first tree.
- –
The interval is contained entirely within the interval , and is a descendant of in a depth first tree.
- –
- •
White-path theorem: In a depth first forest of a graph , vertex is a descendant of vertex if and only if at the time that the search discovers , there is a path from to consisting entirely of white vertices.
Proof:
“”: If is a descendant of , then is discovered after , which means is white when is discovered. And this is true for all vertices on the path from to , since they are all descendants of .
“”: Proof by contradiction. Let be the first vertex on the white path but is not a descendant of . Let be the predecessor of on the white path. By the choice of , we knoe that is a descendant of , hence . ( and can be the same vertex.) Since there is a path from to , will be discovered before finishes, hence . In all, we have , then must be a descendant of .
6.2.2 Classification of Edges
There are four types of edges in a depth first forest:
- •
Tree edges: Edges in the depth first forest. An edge is a tree edge if was first discovered by exploring edge , or to say ’s color is white when edge is examined.
- •
Back edges: Edges that connect a vertex to an ancestor in a depth first tree. An edge is a back edge if at the time is examined, is colored gray.
- •
Forward edges: Edges that connect a vertex to a descendant in a depth first tree. An edge is a forward edge if at the time is examined, is colored black and was discovered later than .
- •
Cross edges: Edges that connect two vertices in different depth first trees. An edge is a cross edge if at the time is examined, is colored black and was discovered earlier than .
In an undirected graph, there are only tree edges and back edges. This is because there is no way to find a vertex that is colored black.
Let be an arbitrary edge of an undirected graph . Without loss of generality, assume that . Hence, the search must discover before it finishes exploring . If the first time that is examined is from , then it is a tree edge. Otherwise, is a back edge, since is still gray when is examined.
6.2.3 DFS and Cycle
A directed graph is acyclic if and only if a depth first search of the graph yields no back edges.
Proof:
“”: If there is a back edge , then we can find a loop that consists of a path from to on the depth first tree, and the edge .
“”: If there is a loop, then there is a back edge. Assume the cycle is . Without loss of generality, assume the first discovered vertex is . Then at time , all other vertices are colored white. By the white-path theorem, is a descendant of . Therefore, is a back edge.
6.2.4 Topological Sort
A topological sort of a directed acyclic graph is a linear ordering of all its vertices such that if contains an edge , then appears before in the ordering. A topological sort can be implemented by depth first search.
| Topological-Sort | |
|---|---|
| 1. | call DFS to compute finishing times for each vertex |
| 2. | as each vertex is finished, insert it onto the front of a linked list |
| 3. | return the linked list of vertices |
Runtime: .
Correctness: For any edge , we need to prove that . Without loss of generality, assume is discovered before . Since in an acyclic graph there is no back edge, must be white or black. If is white, then is a descendant of , and . If is black, then is already set and .
6.2.5 Strongly Connected Components
A directed graph is strongly connected if there is a path from each vertex to every other vertex. Let be a directed graph, and let be the transpose of , which is the graph formed by reversing all edges in . Note that and have the same strongly connected components.
| Strongly-Connected-Components | |
|---|---|
| 1. | call DFS to compute finishing times for each vertex |
| 2. | compute |
| 3. | call DFS, but in the main loop of DFS, consider the vertices in order of decreasing |
| 4. | output the vertices of each tree in the depth first forest formed in line 3 as a separate strongly connected component |
Runtime:
Correctness: Proof by induction. An SCC must be in its own tree in the depth first forest. And we know the SCC containing the root of a depth first tree can be correctly output. Then we make induction on the number of SCC in the graph. If there is only one SCC, then the algorithm is correct (it will contain the root of the depth first tree). Then, if we want to output the SCCs of a graph with SCCs, we can exclude the SCC containing the root of one depth first tree, and output the SCCs of the remaining graph, which has SCCs.
6.3 Minimum Spanning Tree
A spanning tree of a graph is a tree that is a subgraph of and contains all vertices of . A minimum spanning tree of a weighted, connected, undirected graph is a spanning tree of that has minimum weight.
6.3.1 Generic MST Algorithm
| Generic-MST | |
|---|---|
| 1. | |
| 2. | while does not form a spanning tree |
| 3. | find an edge that is safe for |
| 4. | |
| 5. | return |
Correctness: By loop invariant: is a subset of some MST.
6.3.2 Cuts
A cut of an undirected graph is a partition of . An edge crosses the cut if one of its endpoints is in and the other is in . A cut respects a set of edges if no edge in crosses the cut. An edge is a light edge crossing a cut if its weight is the minimum of any edge crossing the cut.
We can prove that if a cut respects a set of edges, then the light edge crossing the cut is safe for . Suppose is a cut of that respects , and let be a light edge crossing the cut. Let be a minimum spanning tree that contains . If , then obviously is safe for . Otherwise, contains a path from to but does not contain . The path from to with added forms a cycle. Since the cut crosses the cycle, there must be another edge in the cycle that crosses the cut. Since is a light edge, we have . Then we can replace with in to get another spanning tree . Noting that is not in , since the cut respects . Hence, contains . Therefore, is safe for .
6.3.3 Kruskal’s Algorithm
Kruskal’s algorithm sorts all the edges in nondecreasing order by weight, and then adds the edges that connect two different components in the current forest.
| Kruskal | |
|---|---|
| 1. | |
| 2. | for each vertex |
| 3. | Make-Set |
| 4. | sort the edges of into nondecreasing order by weight |
| 5. | for each edge , taken in nondecreasing order by weight |
| 6. | if Find-Set Find-Set |
| 7. | |
| 8. | Union |
| 9. | return |
Runtime: The major cost is sorting the edges, which takes time.
6.3.4 Prim’s Algorithm
Prim’s algorithm grows a single tree by adding edges to the tree one by one. We use a min-priority queue to store the vertices.
| Prim | |
|---|---|
| 1. | for each |
| 2. | |
| 3. | |
| 4. | |
| 5. | |
| 6. | while |
| 7. | |
| 8. | for each |
| 9. | if and |
| 10. | |
| 11. | Decrease-Key |
Runtime: Dominated by the Decrease-Key operations, which takes time.
6.4 Single Source Shortest Path
6.4.1 Dijkstra’s Algorithm
We can use Dijkstra’s algorithm to find the shortest path from a single source to all other vertices. The idea is very similar to Prim’s algorithm.
| Dijkstra | |
|---|---|
| 1. | |
| 2. | |
| 3. | Build-Min-Heap |
| 4. | while |
| 5. | |
| 6. | |
| 7. | for each |
| 8. | if |
| 10. | |
| 11. | Decrease-Key |
Runtime: . The Build-Min-Heap takes time. All calls for Extract-Min takes time. All calls for Decrease-Key takes time.
Correctness: Prove by loop invariant: Before each iteration of the while loop, for each vertex , is the weight of the shortest path from to . We can proof the maintenance of the loop invariant by contradiction: If is the first vertex that does not satisfy when it is added to , then we can find a shortest path from to . Let be the last vertex in on the shortest path and be the first vertex in on the shortest path. Notice that might be and might be . By the choice of , we have and . Then we have . However, since the queue choose to be the next vertex, we have . This means all the inequalities are equalities, and we get .
7 Related Concepts
7.1 Asymptotic Notation
7.1.1 Definition of
A function belongs to if there exist constants and such that for all .
An easy way to proof: divide both side by . For example to proof for all .
Similar to and . A function belongs to if there exist constants and such that for all . A function belongs to if there exist constants and such that for all .
In general, big is used to describe the tight bound of a function, big is used to describe the upper bound of a function, and big is used to describe the lower bound of a function.
7.1.2 Little and Little
A function belongs to if . A function belongs to if , or equivalently, belongs to .
7.1.3 Important Inequalities
Every polynomial of grows slower than every polynomial of . That is: .
Every polynomial of grows slower than every exponential . That is: .
7.1.4 Rule of Sum and Rule of Product
Rule of Sum: .
Rule of Product: .
7.2 RAM Model
The RAM model assumes that each elementary operation takes the same amount of time.
7.3 Common Cost Model
Assume the runtime of an algorithm is the number of elementary operations it performs.
7.4 In place
A sorting algorithm is said to be in place if it requires additional space. Hence, merge sort is not in place, since it requires additional space.
7.5 Stable
A sorting algorithm is said to be stable if it preserves the relative order of equal elements.
7.6 Master Theorem
Let and be constants, let be a function, and let be non-negative function for large enough . Then the recurrence has the following asymptotic bounds:
- 1.
If for some constant , then .
- 2.
If for some constant , then .
- 3.
If for some constant , and if for some constant and all sufficiently large , then .
7.7 Acylic Graph
A directed graph is acyclic if it has no directed cycles.
8 Problems from Homework
Problem 1
Explain why the statement “The running time of Algorithm A is at least is meaningless.
Problem 2
Prove by induction that every nonempty binary tree satisfies .