
Artificial Intelligence (H) Final Review Note
Published:
1 Intelligent Agents
1.1 Definition
Agent
An agent is anything that can be viewed as perceiving its environment through sensors and acting upon that environment through actuators. An agent program runs in cycles of perceive, think, and act. An agent function is a mapping from percepts to actions. An agent is a combination of an architecture and a program, which should be complementary and compatible.
Rational Agent
For each possible percept sequence, a rational agent should select an action that is expected to maximize its performance measure, given the evidence provided by the percept sequence and whatever built-in knowledge the agent has.
1.2 PEAS
When we define a rational agent, we group the agent’s performance elements into four categories: Performance measure, Environment, Actuators, and Sensors. This is called the PEAS description.
Example:
For a self-driving car, the PEAS description is as follows:
- •
Performance measure: Safety, legality, passenger comfort, and arrival time.
- •
Environment: Roads, traffic, pedestrians, other cars, weather.
- •
Actuators: Steering wheel, accelerator, brake, signal lights, horn.
- •
Sensors: Cameras, LIDAR, GPS, speedometer, odometer, engine sensors.
1.3 Properties of Environments
Fully Observable vs. Partially Observable
An environment is fully observable if the agent’s sensors give it access to the complete state of the environment at each point in time. Otherwise, the environment is partially observable.
Deterministic vs. Stochastic
If the next state of the environment is completely determined by the current state and the action executed by the agent, the environment is deterministic. Otherwise, the environment is stochastic.
Episodic vs. Sequential
The agent’s experience is divided into episodes. Each episode consists of the agent perceiving and then acting. The choice of action in each episode depends only on the episode itself. In a sequential environment, the current decision could affect all future decisions.
Static vs. Dynamic
If the environment can change while an agent is deliberating (i.e., the environment does not wait for the agent to make a decision), the environment is dynamic. Otherwise, it is static.
Discrete vs. Continuous
A discrete environment has a finite number of percepts and actions. A continuous environment has a continuous range of percepts and actions.
Single-agent vs. Multi-agent
A single-agent environment contains exactly one agent. A multiagent environment contains multiple agents.
Known vs. Unknown
If the designer of the agent have knowledge of the environment, the environment is known. Otherwise, the environment is unknown.
Example:
Consider the following environments:
| Environment | Observable | Deterministic | Agent | Static | Discrete |
|---|---|---|---|---|---|
| 8-puzzle | Yes | Yes | Single-agent | Yes | Yes |
| Chess | Yes | Yes | Multi-agent | Yes | Yes |
| Poker | No | No | Multi-agent | Yes | Yes |
| Car | No | No | Multi-agent | No | No |
1.4 Types of Agents
1.4.1 Simple Reflex Agents
A simple reflex agent selects actions on the basis of the current percept, ignoring the rest of the percept history. It works well in fully observable, deterministic, and static environments with a few states.
Based on its definition, a simple reflex agent only works well in environments where the current percept is sufficient to determine the correct action. In other words, the environment must be fully observable.
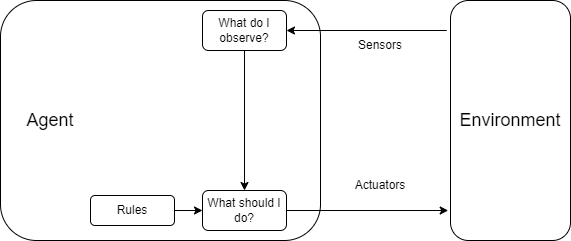
Example:
Consider a simple reflex agent for a vacuum cleaner. The agent has two rules:
- •
If the current location is dirty, then clean.
- •
If the current location is clean, then move to the other location.
This agent works well in a fully observable, deterministic, and static environment with a few states.
1.4.2 Model-based Reflex Agents
A model-based reflex agent maintains an internal state that depends on the percept history and thereby can handle partially observable environments. In other words, a model-based reflex agent learns how the world evolves over time, and uses this knowledge to predict the part of world that it cannot observe, thus making better decisions.
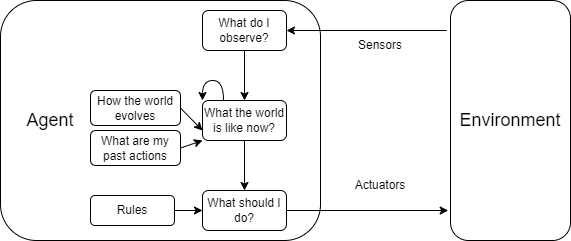
1.4.3 Goal-based Agents
A goal-based agent is an agent that plans ahead to achieve its goals. It uses a goal to decide which action to take. And to do so, it must have the ability to predict the consequences of its actions.
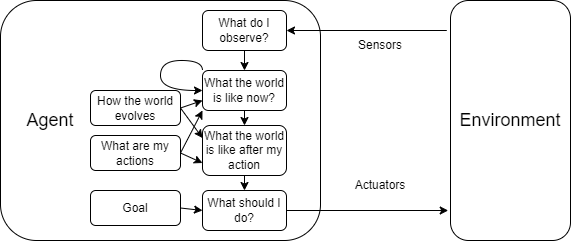
1.4.4 Utility-based Agents
A utility-based agent is an agent that chooses the action that maximizes the expected utility of the agent’s performance measure. It is similar to a goal-based agent, but it uses a utility function to decide which action to take.
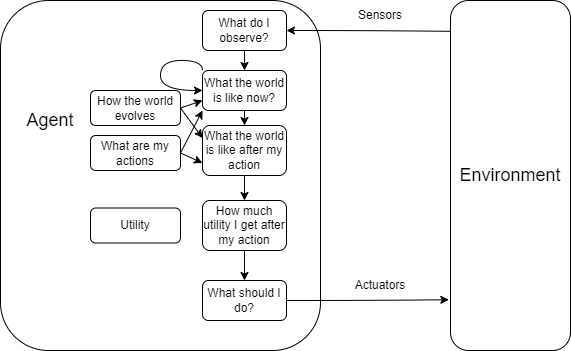
1.4.5 Learning Agents
A learning agent is a generalized agent that can learn from its experience. It has 4 components: a learning element that is responsible for making improvements, a performance element that selects external actions, a critic that provides feedback on how well the agent is doing, and a problem generator that suggests actions that lead to new and informative experiences.
1.5 Agent States
Atomic Representation
An atomic representation assumes each state of the world is a black box without internal structure. For example, in a board game, each state is a unique configuration of the board.
Factored Representation
A factored representation decomposes the state into independent components. These variables can describe the complete state of the world. For example, in a gird-based world, the state can be decomposed into the position of the agent, positions of obstacles and goals, etc.
Structured Representation
A structured representation captures the relationships between components of the state. For example, a map that shows the distances between cities.
2 Search
2.1 Problem Formulation
- •
Initial state: The state in which the agent starts.
- •
States: The set of all reachable states by any sequence of actions.
- •
Actions: The set of all possible actions that the agent can take.
- •
Transition model: A description of what each action does.
- •
Goal test: A function that determines whether a state is a goal state.
- •
Path cost: A function that assigns a numeric cost to each path.
2.2 Search Space
State Space vs. Search Space
The state space is the set of all states reachable from the initial state by any sequence of actions. The search space is an abstract configuration that models the sequence of actions taken by the agent. For example, a search tree is a search space, where its root is the initial state, branches are actions, and nodes result from applying actions to states.
A search space is divided into three parts: frontier, explored set, and unexplored set. The frontier is the set of nodes that have been generated but not yet expanded. The explored set is the set of nodes that have been expanded. The unexplored set is the set of nodes that have not been generated.
2.3 Search Strategies
Strategies are evaluated based on the following criteria:
- •
Completeness: Does the strategy guarantee to find a solution if one exists?
- •
Optimality: Does the strategy guarantee to find the optimal solution?
- •
Time complexity: How long does it take to find a solution?
- •
Space complexity: How much memory does it take to find a solution?
In particular, time complexity and space complexity are measured in terms of following factors:
- •
b: The branching factor, i.e., the maximum number of children of any node.
- •
d: The depth of the solution.
- •
m: The maximum depth of the search tree.
We can classify search strategies into two categories: uninformed search and informed search.
2.3.1 Uninformed Search
- •
Breadth-first search (BFS): Expands the shallowest unexpanded node first.
- •
Depth-first search (DFS): Expands the deepest unexpanded node first.
- •
Depth-limited search (DLS): A variant of DFS that limits the depth of the search.
- •
Iterative deepening search (IDS): A variant of DLS that gradually increases the depth limit.
- •
Uniform-cost search (UCS): Expands the node with the lowest path cost (the same idea used in Dijkstra’s algorithm).
Here are the properties of these strategies:
| Strategy | Completeness | Optimality | Time complexity | Space complexity |
|---|---|---|---|---|
| BFS | Yes if is finite | Yes if cost is the same for every path | ||
| DFS | Yes if the state space is finite | No | ||
| UCS | Yes if the solution has a finite cost | Yes |
Note: is the cost of the optimal solution, and is the minimum cost of any action.
2.3.2 Informed Search
- •
Greedy best-first search: Expands the node that is closest to the goal.
- •
A* search: Expands the node that minimizes , where is the cost to reach from the initial state, and is the estimated cost to reach the goal from .
- •
IDA* search: A variant of A* that uses iterative deepening.
The quality of informed search strategies depends on the quality of the heuristic function.
- •
Admissible heuristic: A heuristic function is admissible if it never overestimates the cost to reach the goal. In other words, , where is the true cost to reach the goal from . An admissible heuristic guarantees to find the optimal solution.
- •
Consistent heuristic: A heuristic function is consistent if for every node and every successor of generated by any action , .
More Info:
The closer the heuristic function is to the true cost, the more efficient the search strategy will be.
- •
If , A* search degenerates into UCS.
- •
If , we no longer need to find the distance by searching, since already gives the distance to the goal.
3 Local Search
3.1 Definition
The search strategies we have discussed so far are called systematic search. For these strategies, when the goal is reached, a solution that consists of a sequence of actions is found.
However, sometimes we do not need to know how to reach the goal (i.e., the sequence of actions). Instead, we only need to know the state that satisfies the goal. In this case, we can use local search.
Example:
AI training is a good example of local search. All we care about is the final model that has the best performance. We do not need to know how the model is trained.
The basic idea of local search is to keep a few states in memory and iteratively improve them. This means we only longer need to store the entire search tree, which saves memory.
Although local search is not guaranteed to find the optimal solution, it often can find a good solution in a reasonable amount of time.
3.2 Local Search Strategies
3.2.1 Hill Climbing
Hill climbing is a simple local search strategy that iteratively improves the current state by moving to the neighboring state with the highest value. However, this might cause the agent to get stuck in a local maximum or a plateau.
Some variants of hill climbing include:
- •
Sideways move: Allow the agent to move to a neighboring state with the same value. This allows the agent to escape plateaus, but not local maxima.
- •
Random-restart hill climbing: Restart the search from a random state.
- •
Stochastic hill climbing: Randomly select the next state among the neighboring states.
- •
Local beam search: Keep states in memory and expand them simultaneously.
- •
Stochastic beam search: Randomly select states among the neighboring states.
3.2.2 Simulated Annealing
Simulated annealing is a variant of hill climbing that allows the agent to move to a neighboring state with a lower value with a certain probability. This probability decreases over time. This allows the agent to escape local maxima.
The probability of moving to a neighboring state with a lower value is given by:
where is the difference in value between the current state and the neighboring state, and is the temperature.
3.2.3 Genetic Algorithms
Genetic algorithms is a variant of stochastic beam search. It is inspired by the process of natural selection. The algorithm maintains a population of states. Successor states are generated by combining two parent states. The algorithm then selects a new population by evaluating the fitness of each state.
The major improvement of genetic algorithms is that produce new states by combining two parent states, not by modifying a single state. This allows the algorithm to explore a larger search space.
3.3 Better Heuristics*
3.3.1 Dominance
The quality of local search strategies depends on the quality of the heuristic function. In the previous section, we discussed the admissible and consistent heuristic functions. However, only looking at these two properties is not enough, because we can easily find many admissible and consistent heuristic functions. To compare different admissible heuristic functions, we consider dominance.
We say that a heuristic function dominates another heuristic function if for all nodes . In other words, is better than if is always greater than or equal to .
More Info:
From a collection of admissible heuristic functions , we can construct a new heuristic function . It is easy to see that dominates all .
3.3.2 Methods to Find Good Heuristics
- •
Relaxation: Relax the problem by removing constraints. For example, in the 8-puzzle, we can relax the constraint that a tile can only move to adjacent empty cells, and allow it to move to any empty cell. Or we can relax the constraint that a tile can move to an occupied cell.
- •
Generated from sub-problems: Only solve a part of the problem, and use the cost of the solution as the heuristic function. For example, in the 8-puzzle, we can solve the problem for half of the tiles, and use the cost of the solution as the heuristic function.
- •
Generated from experience: Use the cost of the solution of similar problems as the heuristic function. For example, in the 8-puzzle, we can use the cost of the solution of similar 8-puzzles as the heuristic function.
4 Adversarial Search
In Adversarial Search, we have an additional utility function that assigns a numeric value to each terminal state for each player. The goal of each player is to maximize its utility. If the sum of the utilities of all players is 0, the game is called a zero-sum game.
4.1 Minimax Algorithm
The minimax algorithm is a search algorithm that is used to find the optimal strategy for a player in a two-player zero-sum game. The algorithm is based on the following idea: if both players play optimally, each player will choose the action that maximizes his utility, and assume that the opponent will choose the action that minimizes his utility (to be noticed that here two “his” represent the same player).
For a state , is:
which represents the maximum utility that can be obtained from state .
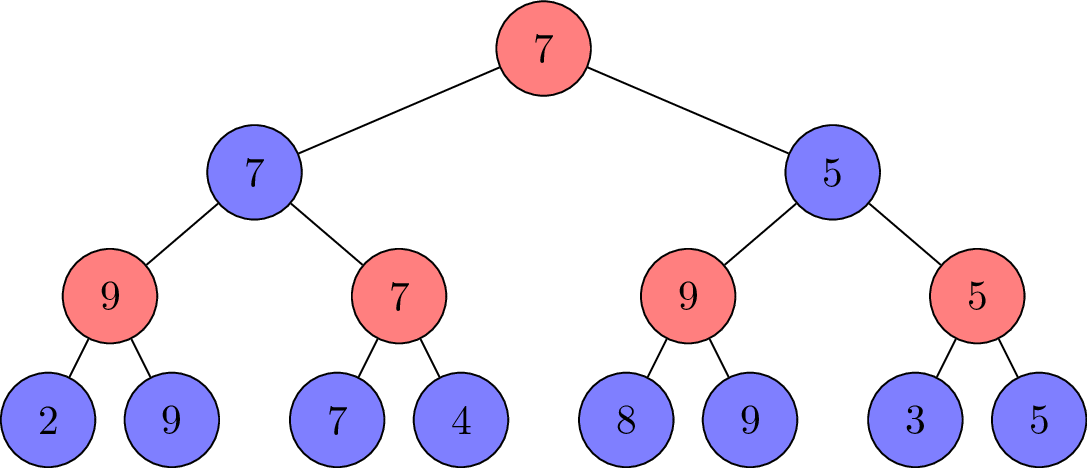
We can observe that the tree is build bottom-up. The algorithm starts from the terminal states and propagates the utility values up to the root.
However, it is not practical to search the entire game tree. And some techniques can be used to improve the performance of the minimax algorithm.
4.1.1 Alpha-Beta Pruning
Alpha-beta pruning is a technique that reduces the number of nodes that need to be evaluated in the minimax algorithm. The idea is that, since the MAX player will choose the maximum value among the children, if we know the value of certain subtree will never be the maximum value, then we do not need to explore it, and same for the MIN player.
For example, below displays an incomplete DFS search tree, where the black nodes are pruned.
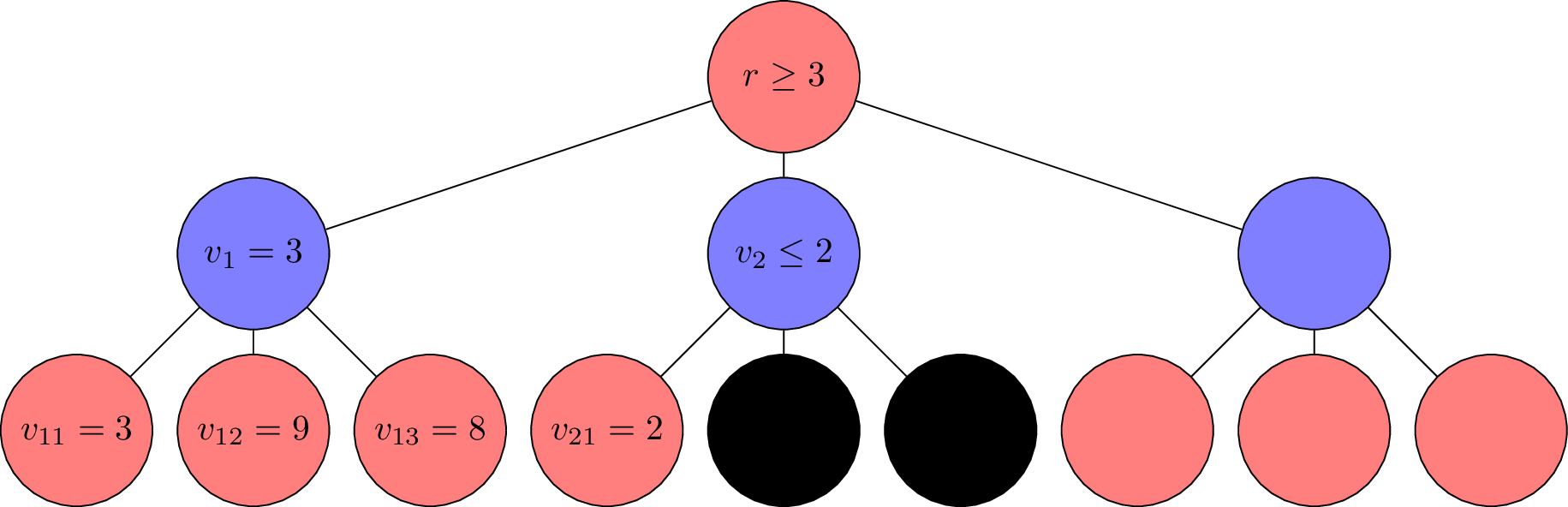
In this example, we discovered that . Since MIN player decide on the value of , he will choose the smallest value among , , and . Since , the value of will never be greater than 2. Then, when MAX player decide on the value of , he will choose the largest value among , and . Since and , he will never choose . Therefore, we can prune the subtree rooted at .
More Info:
Formally, is:
Obviously, the value of can never be greater than 3. Therefore, we can prune the subtree rooted at .
Based on this idea, we can define as the best value that the MAX player has found so far at any choice point along the path for MAX, and as the best value that the MIN player has found so far at any choice point along the path for MIN. Then, we can prune the subtree rooted at a node if for MIN player, or for MAX player.
Here is the pseudocode for the alpha-beta pruning algorithm:
def alphabeta_search(game, state):
player = state.to_move
def max_value(state, alpha, beta):
if game.is_terminal(state):
return game.utility(state, player), None
v, move = -infinity, None
for a in game.actions(state):
v2, _ = min_value(game.result(state, a), alpha, beta)
if v2 > v:
v, move = v2, a
if v >= beta:
return v, move
alpha = max(alpha, v)
return v, move
def min_value(state, alpha, beta):
if game.is_terminal(state):
return game.utility(state, player), None
v, move = infinity, None
for a in game.actions(state):
v2, _ = max_value(game.result(state, a), alpha, beta)
if v2 < v:
v, move = v2, a
if v <= alpha:
return v, move
beta = min(beta, v)
return v, move
return max_value(state, -infinity, +infinity)
4.1.2 Move Ordering
From the process of alpha-beta pruning, we can see that the order of the children of a node is important. If we can find a good ordering, we can prune more nodes.
The ordering of the children of a node is often done by heuristic function, which evaluate the value of each child. For example, an Othello agent can use the difference in the number of pieces as the heuristic function.
4.1.3 Early Cutoffs
Since utility function only provides scores for terminal states, the algorithm must reach the terminal states to evaluate, which is time-consuming. We can use early cutoffs to stop the search early. For example, we find an evaluation function that can estimate the value of a non-terminal state, thus we stop at any moment and use the stated examined so far to decide the best move.
With this technique, we can use iterative deepening, where we gradually increase the depth of the search. This allows us to find a good move in a reasonable amount of time, or to stop the search early if we run out of time.
4.2 Stochastic Games
Stochastic games may include randomness, for example in the form of dice rolls. In this case, we can use the expectiminimax algorithm, which add a new type of node called chance node to the game tree. The value of a chance node is the expected value of its children.
For a state , is:
5 Constraint Satisfaction Problems
For a constraint satisfaction problem (CSP), each state is defined by a set of variables (factored representation), each of which has a domain of possible values , and a set of constraints that specify allowable combinations of values for subsets of variables (unary, binary, global, and soft constraints).
The goal of a CSP is to find an assignment of values to variables that satisfies all constraints. A solution to a CSP is called a consistent assignment.
5.1 Backtracking Search
Backtracking search is a variant of depth-first search that is used to solve CSPs. The major difference is that backtracking search can use inference to reduce the search space.
The algorithm works as follows:
- 1.
Select an unassigned variable.
- 2.
Select a value from the domain of the variable, and assign it to the variable.
- 3.
If the assignment is consistent with the constraints, recursively assign values to the remaining variables. Otherwise, backtrack.
Several techniques can be used to improve the performance of backtracking search:
- •
Minimum remaining values (MRV): When selecting an unassigned variable, choose the variable with the fewest remaining values in its domain.
- •
Least constraining value (LCV): When selecting a value for a variable, choose the value that rules out the fewest values in the remaining variables.
- •
Forward checking: When assigning a value to a variable, check if the remaining variables have any values left in their domains. If not, backtrack.
5.2 Types of Consistency
Node consistency
A variable is node consistent if every value in its domain satisfies the variable’s unary constraints.
Arc consistency
is arc consistent if for every value in the domain of , there is some value in the domain of that satisfies the binary constraint between and .
Path consistency
Generalize arc-consistency for multiple constraints. This is not important because it is always possible to transform all global constraints into binary constraints.
5.2.1 AC-3 Algorithm
The AC-3 algorithm checks whether a CSP is arc consistent. The algorithm works as follows:
The idea of the AC-3 algorithm is that:
- 1.
Build a queue for arcs that need to be checked.
- 2.
Check each arc in the queue. Modify the domain of the first variable until it is arc consistent with the second variable.
- 3.
If the domain of the first variable is empty, the CSP is not arc consistent (no valid assignment for the first variable).
- 4.
Since we modified the domain of the first variable, this may cause some arcs to be inconsistent. Add these arcs to the queue.
The time complexity of the AC-3 algorithm is , where is the number of variables and is the maximum domain size.
6 Logic
6.1 Entailment and Inference
Entailment
A sentence means that is true in all models where is true. In other words, is entailed by .
Inference
Inference is the process of deriving new sentences from existing sentences. It applies rules of inference to to build a new sentence . Inference is denoted as .
Entailment enumerates all possible models of to check if is true in all models, while inference does not.
6.2 Sound and Complete
An inference algorithm we desire should be sound and complete. A sound algorithm is one that never infer a false sentence from a true sentence, while a complete algorithm is one that can infer all true sentences. In other words, a sound and complete algorithm is one that can infer all and only true sentences.
With inference rules, we can guarantee the soundness of algorithm. To achieve completeness, we use resolution or forward/backward chaining.
6.2.1 Resolution
The resolution law can be written as:
where and are complementary literals.
6.2.2 Forward and Backward Chaining
Forward Chaining
Forward chaining is a simple inference algorithm that starts with the known facts and repeatedly applies Modus Ponens to Horn Clauses and add result back to .
Backward Chaining
Backward chaining is goal-driven. It repeatedly checks the premise of target clause. This gives linear complexity in size of .
7 Machine Learning
7.1 Supervised vs. Unsupervised Learning
Supervised Learning
In supervised learning, the algorithm learns from labeled data, where each example is a pair of input and output. The goal is to learn a function that maps inputs to outputs. Within supervised learning, we have two types of tasks: classification (discrete output) and regression (continuous output).
Unsupervised Learning
In unsupervised learning, the algorithm learns from unlabeled data. The goal is to find hidden patterns in the data.
7.1.1 Example: K-Nearest Neighbors
The k-nearest neighbors (KNN) is a simple supervised learning algorithm that can be used for both classification and regression. Although most ML algorithms build a model from the training data, KNN algorithm is an exception.
The core idea of the KNN algorithm that two data points are similar if they are close to each other, and two similar data points should have the same label. The algorithm works as follows:
- •
Train Add all data points to the training set.
- •
Predict
- 1.
For a new data point, calculate the distance between the new data point and all data points in the training set. For this step, we can use Euclidean distance, Manhattan distance, etc.
- 2.
Select the nearest data points.
- –
For classification, return the most common label among the nearest data points.
- –
For regression, return the average value of the nearest data points.
- –
- 1.
The pros and cons of KNN are:
- •
Pros
- –
Simple
- –
No training phase
- –
No model or hyperparameters, no assumptions about the data
- –
- •
Cons
- –
Slow prediction phase (, where is the number of data points and is the number of features)
- –
Require large dataset
- –
Sensitive to the distance metric
- –
Suffers from the curse of dimensionality
- –
7.2 Train, Validate and Test
7.2.1 Loss Function
To evaluate the performance of a model, we need a loss function that measures the difference between the predicted value and the true value. Different tasks require different loss functions.
For classification tasks, we often use the cross-entropy loss, which is defined as:
where is the true label in one-hot encoding, and is the predicted probability.
For regression tasks, we often use the mean squared error (MSE), which is defined as:
7.2.2 Structural Risk Minimization
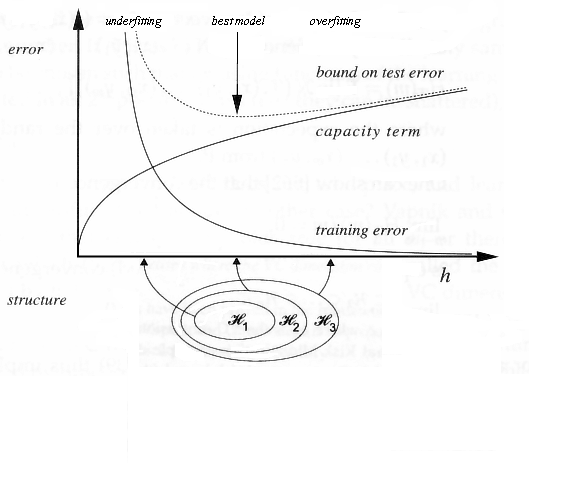
When we train a model, we want to find a balance between underfitting and overfitting. Underfitting occurs when the model is too simple to capture the underlying pattern in the data, while overfitting occurs when the model is too complex and captures noise in the data.
Underfitting is featured by high bias and low variance, with high training error and high test error. Overfitting is featured by low bias and high variance, with low training error and high test error.
To avoid overfitting, here are some techniques:
- •
Feature selection: Remove irrelevant features.
- •
Regularization: Add a penalty term to the loss function.
- •
Cross-validation: Estimate the test error with a validation set.
- •
Model selection: Choose a simpler model (lower degree polynomial, smaller neural network, etc.).
7.2.3 K-Fold Cross-Validation
K-fold cross-validation is a technique that estimates the test error by splitting the training set into folds. The algorithm works as follows:
- 1.
Randomly partition the training set into equal-sized subsets, denoted as .
- 2.
For , train the model on and evaluate the model on .
- 3.
Calculate the average test error.
7.2.4 Confusion Matrix
A confusion matrix is a table that is often used to describe the performance of a classification model. An example of a confusion matrix is shown below:
| Predicted Positive | Predicted Negative | |
|---|---|---|
| Actual Positive | True Positive (TP) | False Negative (FN) |
| Actual Negative | False Positive (FP) | True Negative (TN) |
Some common metrics that can be calculated from a confusion matrix include:
- •
Accuracy: , the proportion of correct predictions.
- •
Precision: , the proportion of positive predictions that are correct.
- •
Recall: , the proportion of actual positives that are correctly predicted.
- •
F1 score: , the harmonic mean of precision and recall.
8 Regression
8.1 Linear Regression
A linear regression model is a linear model (i.e., the output is a linear combination of the input features) that is used to predict a continuous value. The model is defined as:
where is the predicted value, is the bias term, are the weights, are the input features, and is the dimension of the input features.
The goal of linear regression is to find the weights that minimize the mean squared error (MSE) between the predicted value and the true value. The loss function is defined as:
where is the true value, is the predicted value, and is the number of data points.
8.1.1 Normal Equation
Let , , and .
Then the loss function can be written as:
The unique solution to the normal equation is:
However, the normal equation has some limitations:
- •
We cannot guarantee that exists. In some extreme cases (for example, when ), we can prove that does not exist.
- •
Even if exists, the time complexity for matrix inversion is , which is not efficient for large .
- •
Due to its linear nature, the normal equation cannot capture non-linear relationships between the input features and the output.
8.1.2 Gradient Descent
Gradient descent is an iterative optimization algorithm that is used to find the weights that minimize the loss function. The algorithm works as follows:
- 1.
Initialize the weights randomly.
- 2.
Calculate the gradient of the loss function with respect to the weights: .
- 3.
Update the weights: , where is the learning rate.
- 4.
Repeat steps 2 and 3 until the weights converge.
Example:
For a first order linear regression model defined as:
the update rule for gradient descent is:
8.2 Logistic Regression
Logistic regression is a linear model that is used to predict the probability of a binary outcome. The model is defined as:
where is the sigmoid function.
The loss function for logistic regression is the cross-entropy loss, which is defined as:
9 Support Vector Machine
A support vector machine (SVM) is a supervised learning algorithm that is used for classification tasks. The goal of an SVM is to find the hyperplane that separates the data points of different classes with the maximum margin.
9.1 Linear SVM
One challenge met by linear regression is that many hyperplanes can separate the data points, but which one is the best? SVM solves this problem. The core idea of linear SVM is to find a hyperplane that its minimum distance to any data point is maximized. Although the idea looks simple, the mathematical formulation of the problem is complex, however beautiful.
A linear SVM is a linear model that is defined as:
where sign is the sign function, defined as:
The decision boundary of an SVM is defined as:
Since we have a decision boundary, we can find the minimum distance between the decision boundary and the closest data point. This distance is called the margin. Now we define the plus-plane as and the minus-plane as . For any point, its distance to the decision boundary is at least .
To simplify the problem, we can scale the weights and the bias term by (i.e., and ). Now the plus-plane becomes and the minus-plane becomes . For any point, its distance to the decision boundary is at least 1.
Finally, we can define the margin as the distance between the plus-plane and the minus-plane, which is . Any data point that is on the plus-plane or the minus-plane is called a support vector.
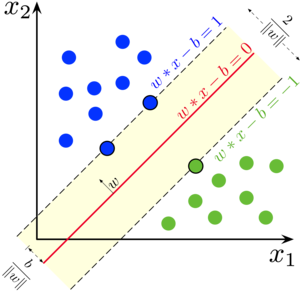
The goal of an SVM is to maximize the margin. This has a clear interpretation: the larger the margin, the more separation between the classes.
Now, if we skip the derivation, we can find that the optimization problem of an SVM can be simply written as:
where is the label of the -th data point.
9.1.1 Solving the Optimization Problem
The optimization problem of an SVM is a quadratic programming problem. We can use the Lagrange duality to solve it.
Construct the Lagrangian
The Lagrangian of the optimization problem is:
where are the Lagrange multipliers.
Find the Dual Problem
The dual problem is:
Using any optimization algorithm, we can find the optimal .
Find the Optimal Weights
The optimal weights can be calculated as:
Find the Optimal Bias Term
The optimal bias term can be calculated as:
Example:
KKT complementarity conditions tell us that, after we find the optimal , all support vectors have and all other data points have .
9.1.2 Soft Margin SVM
Sometimes, the data points are not linearly separable. In this case, we can use a soft margin SVM, which allows some data points to be misclassified. The optimization problem of a soft margin SVM is:
where is the penalty term that controls the trade-off between the margin and the number of misclassified data points. The larger the value of , the more the model will try to classify all data points correctly.
9.2 Kernel SVM
The limitation of linear SVM is that it can only find a linear decision boundary. To find a non-linear decision boundary, we can use kernel SVM.
The core idea of kernel SVM is to map the input features into a higher-dimensional space, where the data points are linearly separable. In other words, each data point is mapped into a higher-dimensional space , where .
More directly, since the ultimate goal is to solve the dual problem, the kernel function modifies the dual problem equation. The dual problem of kernel SVM is:
where is the kernel function.
When , the dual problem equation degenerates to the linear SVM. For non-linear decision boundaries, we can use different kernel functions, such as the polynomial kernel () and the Gaussian kernel ().
10 Perceptron & Neural Networks
10.1 Perceptron
A perceptron is a simple supervised learning algorithm that is used for binary classification tasks. The goal of a perceptron is to find the hyperplane that separates the data points of different classes. The model is defined as:
The perceptron algorithm is an iterative optimization algorithm that is used to find the weights that minimize the loss function. The algorithm works as follows:
- 1.
Initialize the weights randomly.
- 2.
For each data point , calculate the predicted value .
- 3.
If the predicted value is incorrect, update the weights: and (sometimes we use a learning rate to control the update).
- 4.
Repeat steps 2 and 3 until the weights converge.
10.2 Neural Networks
Perceptron is powerful enough to represent many boolean functions. However, it is not powerful enough to represent XOR function. To solve this problem, we can use neural networks.
One major change in neural networks is that we add more layers between the input layer and the output layer. These layers are called hidden layers. Another change is that we use activation functions to introduce non-linearity to the model (sign function, also called step function, is not suitable since it is not differentiable, thus cannot be used in backpropagation).
10.2.1 XOR Problem
The XOR problem is a classic example that shows the limitation of linear models, since its special property makes it impossible to be solved by a single perceptron.
However, we can solve the XOR problem using a neural network with one hidden layer. First, we transform the XOR function into:
Then, we can use a neural network with one hidden layer to represent the XOR function. Suppose the input value , and the activation function outputs 1 if the input is positive and 0 otherwise. The neural network can be represented as:
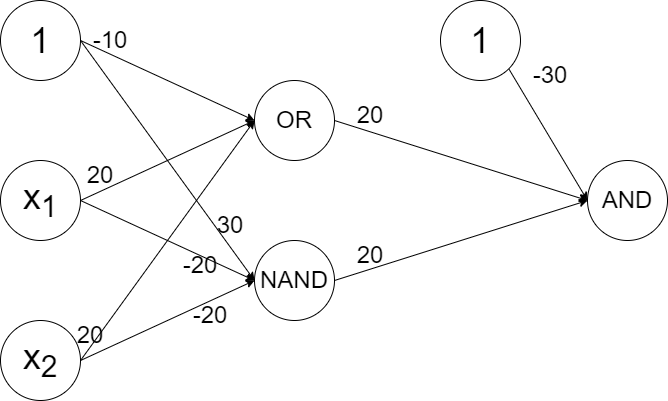
10.2.2 Backpropagation
Since neural network introduce hidden layers, we need a new algorithm to determine how to update the weights for each layer (since no label is given for hidden layers). The backpropagation algorithm is used to update the weights of a neural network.
The core idea for backpropagation is:
This equation can be calculated layer by layer, starting from the output layer.
11 Decision Trees
A decision tree is build from top to bottom. At each step, we choose the best feature to split the data. The goal is to maximize the information gain, which is defined as:
where is the entropy of a set .
Noticing that the entropy of a set reaches its maximum when all classes are equally distributed, and reaches its minimum when all data points belong to the same class. The more information gain, the lower the entropy of the child nodes, the purer the child nodes.
To avoid overfitting, we can prune the tree backward. Or we can early stop the tree building process. The former is better, since we can use a validation set to determine the best time to stop.
CART
CART is a variant of decision tree that uses the Gini impurity to measure the impurity of a set. The Gini impurity is defined as:
12 Naive Bayes
The Naive Bayes algorithm is a simple supervised learning algorithm that is used for classification tasks. The algorithm is based on Bayes’ theorem, which is defined as:
The Naive Bayes algorithm assumes that the features are conditionally independent given the class label, which means we can modify the Bayes’ theorem as:
However, this assumption is not always true. Hence, the algorithm is called "naive". Despite this, the Naive Bayes algorithm is still widely used in practice due to its simplicity and efficiency.
The Naive Bayes algorithm works as follows:
- 1.
Given a training dataset with data points and features, where the -th data point is represented as , calculate the prior probability and the conditional probability for each feature .
- 2.
For a new data point , calculate the posterior probability for each class label .
Example:
For a simple 2 feature dataset with 6 data points:
| Feature 1 | Feature 2 | Class Label |
| 1 | 1 | 0 |
| 1 | 0 | 1 |
| 0 | 1 | 1 |
| 0 | 1 | 0 |
| 1 | 1 | 1 |
| 1 | 0 | 1 |
The prior probability is:
The conditional probability is:
For a new data point , the posterior probability is:
Since , the predicted class label is 1.
13 Ensemble Learning
An ensemble method combines the predictions of multiple models to improve the overall performance. Some representative ensemble methods include bagging, boosting, and ramdom forest.
13.1 Boosting
The core idea of boosting is to train multiple weak learners sequentially, where each weak learner is trained to correct the mistakes of the previous weak learners.
Firstly, we define the error of a weak learner as:
where is the weight of the -th data point, is the true label, is the predicted label, and is the indicator function (1 if the condition is true, 0 otherwise).
Then, we can calculate the weight of the weak learner as:
We the update the weight of each data point as:
The workflow of boosting is:
- 1.
Initialize the weights of the data points as .
- 2.
For :
- (a)
Train a weak learner based on the weighted data points.
- (b)
Calculate the error of .
- (c)
Calculate the weight of .
- (d)
Update the weights of the data points based on the predictions of .
- (a)
- 3.
Combine the weak learners using the weights.
For the final prediction, we can use the weighted sum of the predictions of the weak learners:
13.2 Bagging
The core idea of bagging is to train multiple models in parallel, where each model is trained on a random subset of the data points. The final prediction is the average of the predictions of the models.
13.3 Random Forest
Random forest is an ensemble method that combines the ideas of bagging and decision trees. The core idea of random forest is to train multiple decision trees in parallel, where each decision tree is trained on a random subset of features.
14 Clustering
Clustering is an unsupervised learning algorithm that is used to group similar data points together. Some representative clustering algorithms include K-means, DBSCAN, and hierarchical clustering.
14.1 K-Means
The K-means algorithm is a simple clustering algorithm that is used to partition the data points into clusters. The algorithm works as follows:
- 1.
Initialize the centroids of the clusters randomly.
- 2.
Assign each data point to the nearest centroid.
- 3.
Update the centroids by taking the average of the data points in each cluster.
- 4.
Repeat steps 2 and 3 until the centroids converge.
14.1.1 How to Choose
Elbow method
We can use the elbow method to determine the optimal number of clusters, which means we plot the loss function (e.g., the sum of squared errors) against the number of clusters and choose the number of clusters that corresponds to the "elbow" point.
G-means
G-means is a variant of K-means that uses a statistical test to determine the optimal number of clusters. The algorithm works as follows:
- 1.
Initialize as a small number.
- 2.
Run K-means with clusters.
- 3.
For each cluster, perform a statistical test to determine if the cluster fits a Gaussian distribution.
- 4.
If the cluster does not fit a Gaussian distribution, split the cluster into two sub-clusters.
- 5.
Repeat steps 2 to 4 until all clusters fit a Gaussian distribution.
14.1.2 How to Evaluate Clustering
Internal Evaluation
Internal evaluation metrics consider the distance between data points within the same cluster and the distance between data points in different clusters. Some common internal evaluation metrics include the silhouette score and the Davies-Bouldin index.
External Evaluation
External evaluation metrics compare the clustering results with the ground truth labels. Some common external evaluation metrics include the adjusted Rand index and the Fowlkes-Mallows index.
14.1.3 How to Cluster Non-Circular Data
Use kernel K-means, which maps the data points into a higher-dimensional space where the data points are linearly separable. Other methods include spectral clustering and DBSCAN.
14.1.4 How to Initialize Centroids
The initialization of centroids can affect the performance of the K-means algorithm. Some common methods for initializing centroids include:
- •
Initialize the centroids randomly.
- •
Choose each centroid furthest from the previous centroids.
- •
Try multiple initializations and choose the one with the lowest loss.